


Apache Pulsar is a distributed messaging and streaming platform created and open-sourced by Yahoo. Its effectiveness has seen it applied beyond pub/sub messaging — all the way to scalable storage. As a result, developers began to see the potential of Pulsar for faster retrieval of real-time data.
The best way to achieve this is to query data as it arrives rather than when it is in a stored system, such as a database. The faster retrieval of real-time data is the need that led to the development of Pulsar SQL.
This article explores how Pulsar SQL queries data and the components involved. It also walks through an SQL query example.
Making the Most of Pulsar SQL
Pulsar SQL is a query layer that sits on top of Apache Pulsar and enables users to query structured data streams stored inside Pulsar. This includes live incoming streams and older stored streams.
The Pulsar SQL layer relies on Trino — a fast, distributed SQL query engine — to query event streams. This querying process occurs in a Presto cluster. Presto is a distributed system that runs a cluster of machines, with each cluster containing a coordinator and multiple workers. Presto workers use the Pulsar Presto connector to access the Pulsar event streams stored in an Apache Bookkeeper node called a bookie.
Use Case
Pulsar querying can be instrumental in cases that require real-time analytics. For instance, consider an eCommerce website that recommends products to its users. In such a case, a query can provide real-time feedback when the customer purchases to ensure that their recommendations list is updated accordingly. This might then entail recommending complementary products and removing similar products from the recommendation list.
Pulsar’s Storage Layer
Pulsar uses brokers to organize the messages that producers publish, then store them as segments in Apache Bookkeeper — a scalable and low latency storage service for real-time workloads. Its features make it an ideal solution for Pulsar’s persistent message storage needs. Each of the topics received is replicated to a bookie, guaranteeing that messages the broker receives will be delivered to the intended consumer.
The replication of messages ensures they are durable and available in two or more servers with mirrored redundant arrays of independent disk (RAID) volumes.
Consider the eCommerce example in the previous section. When you click to view an item, an event is triggered. Then, a different event begins when you click to purchase the item. A broker then receives these generated event streams and organizes them based on the topic. They are then replicated and stored in bookies before being processed as database updates.
However, to enhance the user experience and encourage more customer engagement, it’s crucial to populate the webpage with relevant, meaningful recommendations as quickly as possible. That’s where Pulsar SQL comes in. By reading the viewing and purchasing event streams directly from bookies, Pulsar provides the system’s recommender code with the necessary information to create new recommendations before the user has left the site.
Querying Versus Streaming and Messaging in Apache Pulsar
Let’s start by understanding an event. An event is a data point generated by a system or producer after a specific occurrence. Streaming and messaging in Pulsar involves the continuous creation of those data points. The data generated by producers must follow a structure defined by a schema and enforced by Pulsar’s registry. A broker forwards that data to the Bookkeeper to store as segments, which are then organized based on topics. The broker replicates those segments before temporarily storing them in the bookies.
Organizing the received data streams into topics makes it easier for consumers to read data through a broker. However, this process is not as fast because the broker must first authenticate the consumer’s request and verify the schema.
In contrast, querying in Pulsar involves reading the data streams directly from the bookies. This is possible because the data streams in the bookies follow the structure specified by the schema.
The difference between message consumption and querying is that the latter doesn’t care about sequence — it is only interested in reading the event streams. Pulsar SQL reads event streams as soon as the bookie receives the stream segments.
The Consumer API handles message consumption, designed for the pub/sub model, and is ineffective in reading data in bulk. It also requires the data to be organized in topics and ordered in a prescribed manner.
Pulsar SQL in Action
In this section, you run a local Pulsar cluster in standalone mode using Docker Desktop. First, ensure you have Docker Desktop installed. If you don’t, download it here and follow the installation instructions.
Once you’re set-up, start the Pulsar Cluster in Standalone mode in a Docker container by executing the following command in the terminal:
| |
Note:
- For Windows, configure Docker Desktop to use Linux Containers.
- For macOS, add the
--platform=linux/amd64flag to specify the architecture and OS.
Wait for the Pulsar standalone container build to complete before proceeding. You can verify that the container has been created by running this command on a new terminal:
| |
Make a note of the container ID because you use it in the next step.
To execute the commands for this project inside the Pulsar container you just created, connect to the container using this command:
| |
(Replace <CONTAINER ID> with the ID you noted in the previous step.)
You now have a running Pulsar cluster. This cluster s what you use to execute Pulsar SQL queries. But first, you must start a Pulsar worker on the Pulsar standalone container you just created:
| |
Note that this command only works after the Pulsar standalone container build is complete.
Now you can start using the SQL command-line interface (CLI). Initiate it by executing the command below:
| |
If this is successful, your terminal should change and start with presto>.
You can test the SQL capabilities by executing a few queries.
- Check the catalogs:
show catalogs; - Check the schemas:
show schemas in pulsar; - Check the tables available with
show tables in pulsar."public/default";
Now create some mock data that you can query. To create the mock data, you need a built-in connector called DataGeneratorSource.
First, type “Q” in the terminal to quit the SQL CLI and return to the container terminal. Start by downloading the necessary connector using CURL:
| |
Create a directory and name it connectors:
| |
Then, move the data-generator connector to the connectors directory.
| |
Reload the connector to complete its installation:
| |
Verify that the installed connector is ready for use:
| |
You should get a list of all installed connectors, including the pulsar-io-data-generator-2.10.0.nar. The output should look like this:

Last, create the mock data.
| |
The command above creates the topic generator_test in the public/default namespace using the data-generator connector.
Querying Data Using SQL
Start by going back to the SQL CLI using this command:
| |
Now, you can query a topic in the namespace "public/default."
| |
If successful, the output should look like this:
Table
----------------
generator_test
(1 row)
Query 20180829_213202_00000_csyeu, FINISHED, 1 node
Splits: 19 total, 19 done (100.00%)
0:02 [1 rows, 38B] [0 rows/s, 17B/s]
Now query the data from the topic generator_test.
| |
You should see the data arriving as it is generated:
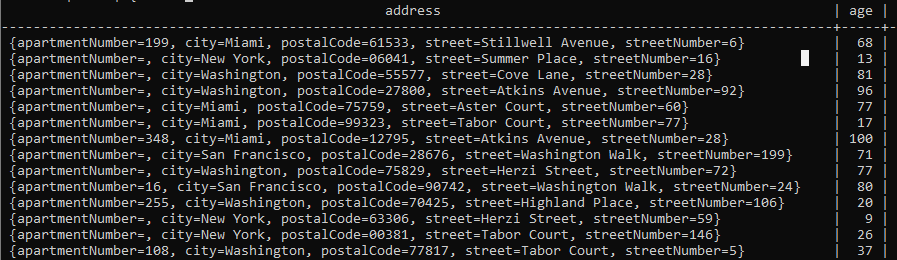
To quit the stream, enter the letter q in the terminal.
You can also create a custom query that filters the data you want. ou should base the custom query you create here on your project’s generated data.
| |
The output is:
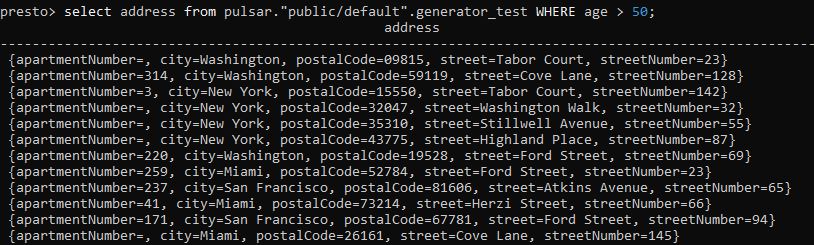
You can make most of the queries with regular SQL while using Pulsar SQL. For instance, you can use: AND, AT, EXCEPT, FETCH, GROUP, HAVING, INTERSECT, LIMIT, OFFSET, OR, ORDER, and UNION.
In the example above, you successfully queried structured data streams. The response was structured and in line with the query executed.
Using the Presto Java Database Connectivity Driver
You can also access Presto via the Presto Java Database Connectivity (JDBC) driver. Java applications can use the Presto JDBC driver to access and perform operations on structured data using query methods such as CREATE, DELETE, UPDATE, and INSERT, among others. With the Presto JDBC driver, you can query topics from clusters that organize structured data in topics. This powerful tool allows you to create complex queries at scale.
The JDBC driver provides a powerful suite of tools for managing Pulsar SQL directly from Java applications. While the Presto shell provides a direct method of working with SQL in Pulsar, the JDBC driver is a go-to solution for creating Java applications that incorporate Pulsar SQL and allows for more complex integrations of Pulsar SQL into application logic.
Conclusion
You use Pulsar SQL to query event streams from the Pulsar bookies and fetch data streams from persistent storage. Presto workers do the actual querying by using Presto Pulsar connectors. This enables you to create custom queries just like you would while querying an SQL database.
Pulsar SQL provides powerful data processing and manipulation capabilities, prioritizing speed without sacrificing function.






