


An All In One Messaging System
✏️ Ivan Garcia / 📆 Feb 2022 / 🕑 15 min read
https://github.com/IvanGDR/Pulsar-Queuing-and-Streaming
In this first delivery of this blog series over apache Pulsar, the aim is to provide an introductory reading about this topic. I would also like to focus this reading on what is Pulsar and how it works under its own merits rather than comparing it against apache Kafka. I am taking this approach as there is plenty literature doing this already and because from a messaging system architecture both of these paradigms, up to a point, are different.
What is Apache Pulsar?
Apache Pulsar is an open-source distributed publish-subscrib messaging system with a robust, highly available, high performance streaming messaging platform, offering messaging consumption, acknowledging and retention facilities as well as tenant implementation options.
Tenant Implementation
On a high level view, Apache Pulsar has been conceived to support multi-tenant deployments. The key pieces that allows this configuration topology are: properties and namespaces.
!!! An analogy for this would be:
Pulsar Cluster(s) = Company (Regional Branches)
Propert(y/ies) = Department(s)
Namespace(s) = Operative action(s)

Fig. 1: Apache Pulsar tenant facilities.
Message Consumption
In a lower level view, the Apache Pulsar Model is based on the following components:
Producer -> Topic <–> Subscription <- Consumer
1. Producer: It is the application that sends messages to the topic and each message sent by the publisher is only stored once on a topic partition. It uses a Routing to determine which internal topic a message should be published to.
2. Topic (partition): It is the place where all the messages arrive. Each topic partition (stateless) is backed by a distributed log stored in Apache BookKeeper (stateful). The partition is the core resource in Pulsar, that performs the critical administrative operations inherited from the namespace in which it resides. Furthermore these namespaces can have a local or global scope. By default Pulsar Topics are created as non-partitioned but this can be modified to obtain high throughput to manage big data. As Producers and consumers are partition agnostic, a non-partitioned topic can be converted into partitioned on the fly (modifying the BROKER process), it is a pure administrative task.
3. Subscription: Determines which consumer(s) a message should be delivered to. Each topic can have multiple subscriptions and a subscription can have one or more consumer group(s). There are three types of subscriptions that can co-exist on the same topic:
- Exclusive Subscription: For streaming use case. One consumer only in order to respect ordered consumption.
- Failover Subscription: For streaming use case. Two consumers but one active only in order to respect ordered consumption.
- Shared Subscription: For queuing use case. Multiple consumers can be active, allowing consumption in an unordered manner.
4. Consumer: It is the application that reads messages from Pulsar. These are grouped together for consuming messages. Each consumer group can have its own way of consuming the messages.

Fig. 2: Apache Pulsar Model and Message Consumption
Message Acknowledgement
These implementation policies apply in case there is a system failure situation and message(s) cannot be delivered in time.
Pulsar provides both cumulative acknowledgment and individual acknowledgment. In cumulative acknowledgement, any message before the acknowledged message will not be redelivered or consumed again. In individual acknowledgment, only the messages marked as acknowledged will not be redelivered in the case of failure.
For both exclusive or failover subscriptions (streaming) cumulative or individual acknowledge can be applied. For shared subscription (queuing) only individual acknowledge is applicable.
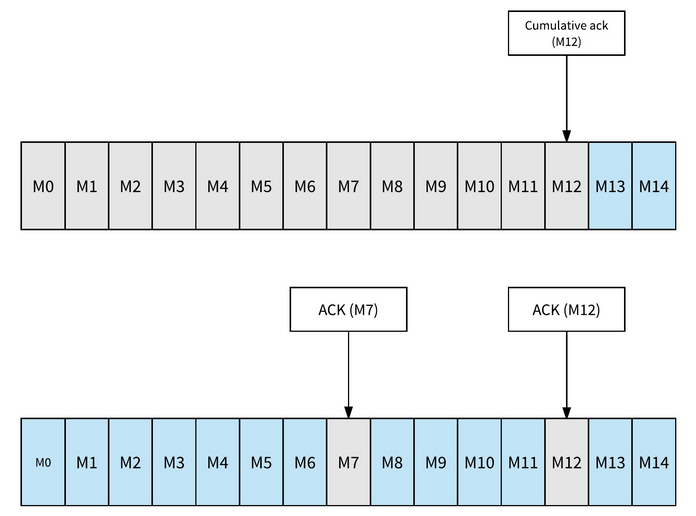
Fig. 3: Cumulative (above) vs Individual (below) Message Acknowledgment, blue cells will be redelivered.
Message Retention and Time To Live (TTL) Policies
A Pulsar cluster consists of 2 fundamental layers: a set of brokers as a serving layer, and a set of bookie nodes as a persistent storage layer. The Brokers as stateless components handle the partitioned parts of topics: store the received messages to the cluster, retrieve messages from the cluster, and send to the consumers on demand. The physical storage of the messages is handled by “bookie” nodes, which are the persistent storage for the Pulsar cluster. The Apache BookKeeper is the configuration used to manage bookie nodes. Since the broker layer and bookie layer are separated, scaling one layer is independent of scaling the other.
Having said that, in Pulsar, messages can only be deleted after all the subscriptions have already consumed it (the messages are marked as acknowledged in their cursors). However, Pulsar also allows to keep messages for a longer time even after all subscriptions have already consumed them. This is done by configuring a message retention period. Additionally, Pulsar allows TTL, a message will automatically be marked as acknowledged if it is not consumed by any consumers within the configured TTL time period.

Fig. 4: Pulsar message retention policies.
!!! Fig 4 interpretation
Figure 4 shows how retention policies work with and without retention policy in place in a topic partition.
Without retention policy, Grey cells can be deleted as these have been acknowledged by subscriptions A and B.
Blue cells cannot be deleted yet as not acknowledged by subscription A.
Green cells cannot be deleted as not acknowledged by any subscription.
Using retention policy, only grey cells can be marked as retained, for the configured time period, as both
subscription A and B have consumed those messages.
On this topic partition subscription B has a TTL in place, cell M10 has been marked as acknowledged even if
this cell has not been consumed yet.
Pulsar Arquitecture
In order to configure a highly available Pulsar multicluster, the following is required:
- A zookeeper ensemble (Local Zk for Pulsar and Bookeeper metadata and Global Zk for Store multicluster metadata)
- A Bookeeper cluster (Stateful storage layer)
- A Pulsar broker cluster (Stateless coordinator)

Fig. 5: Pulsar architecture stack.
Conclusion
In this first part of a trio blog, I reviewed the principal concepts of Apache Pulsar, briefly considering a high and low level description and highlighting the main benefits that it offers, as for example, robust unified messaging system, streaming and queuing paradigms support, multi tenancy facilities, geo replication, retention policies, high availability and big data performance amongst others. In my next blogs I will walk through the installation of a high available Pulsar cluster and finally conclude the blog series with an overview of the logs location and analysis as an attempt to understand how the stack is being built up in order to troubleshoot and solve any potential connection problem that may happen within one or more of the components that Pulsar utilises.




